How I built it
- Pulled a labelled histopathology image set from Kaggle, split 80/20 into train and test, then layered on resize, normalisation, rotation, scaling, flipping, and histogram-equalisation preprocessing to broaden the training distribution.
- Built a custom CNN from scratch (convolutional + ReLU + pooling + fully-connected layers, tuned filter and kernel sizes for cell-level texture).
- Fine-tuned pretrained VGG16 and ResNet50 with transfer learning, customising the heads for binary benign-vs-malignant classification.
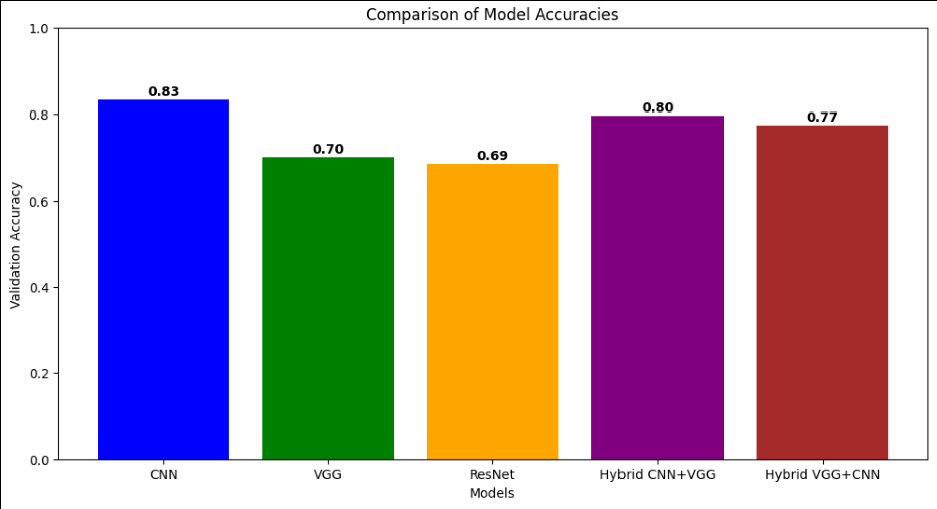
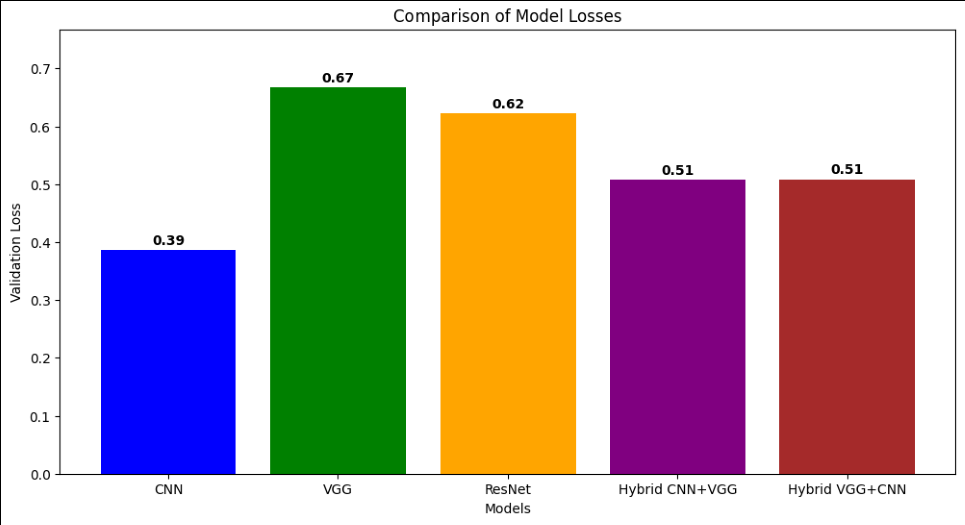
- Trained two hybrid stacks: CNN to VGG (CNN feature extraction feeding VGG depth) and VGG to CNN (the reverse order), to test whether mixing the architectures beat the best single model.
- Used stratified k-fold cross-validation so every fold was used for both training and validation, and ran statistical-significance tests across architectures so the comparison wasn't just "this number was bigger".